Other
📚
Other
Intermediate
derin_ogr_3
tenserflow ve keras kullanarak el yazısını anlayan model eğitin (eğitim için mnsit veriseti kullanılır)

15
cards
124
views
81
studied
Quick Preview
Interactive
TERM
Loading...
DEFINITION
Loading...
1
TERM
MNIST veri setini yükleme

DEFINITION
Ne oluyor?
MNIST: 0–9 arası el yazısı rakamlar
x_train: 60.000 adet 28×28 gri tonlu resim
y_train: her resmin etiketi (0–9)
Piksel değerleri 0–255 arasında
📌 Bu yüzden min = 0, max = 255 görüyorsun.
2
TERM
Tek bir görüntüyü görselleştirme

DEFINITION
Amaç:
Modelin neyle beslendiğini gözünle görmek
Görüntünün etiketiyle eşleştiğini doğrulamak
Bu adım debug + sezgi kazanma içindir.
3
TERM
İlk 25 görüntüyü topluca gösterme

DEFINITION
Amaç:
Verinin genel yapısını görmek
Etiket–görüntü uyumunu kontrol etmek
📌 Bu adım eğitim için şart değil ama çok sağlıklı.
4
TERM
Veriyi modele uygun hale getirme (ÇOK KRİTİK)

DEFINITION
Burada 3 şey oluyor:
1️⃣ Flatten
28×28 → 784
Çünkü Dense layer vektör ister
2️⃣ Normalizasyon
0–255 → 0–1
Eğitim çok daha stabil olur
3️⃣ Float32
GPU uyumlu
Daha hızlı
📌 Bu adım olmazsa model zor öğrenir.
5
TERM
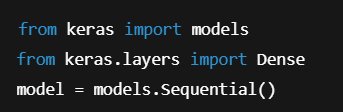
Modeli oluşturma
DEFINITION
Ne demek?
Sequential = katmanlar sırayla akar
En basit MLP mimarisi
6
TERM
İlk katman: giriş + temel özellikler

DEFINITION
Ne oluyor?
Model her resmi 784 sayılık bir vektör olarak alıyor
(28 × 28 = 784)
Bu 784 sayı:
32 farklı “bakış açısından” yorumlanıyor
Yani 32 nöron, resmi 32 farklı şekilde özetliyor
ReLU:
Anlamlı sinyalleri geçiriyor
Gereksiz negatifleri bastırıyor
Çıktı:
784 → 32 özellik
7
TERM
İkinci katman: daha karmaşık öğrenme

DEFINITION
Ne oluyor?
Bir önceki katmandan gelen 32 özellik
Şimdi 64 yeni özellike dönüştürülüyor
Bu katman:
Çizgileri
Eğrileri
Rakamların parçalarını
birleştirmeyi öğrenir.
Çıktı:
32 → 64 özellik
8
TERM
Üçüncü katman: karar katmanı

DEFINITION
Ne oluyor?
64 özellik alınıyor
10 sayı üretiliyor
Her sayı:
“Bu görüntü şu rakam olma ihtimali”
Softmax sayesinde:
Hepsi 0–1 arasında
Toplamları 1
Çıktı:
10 sınıf için 10 olasılık
Bu zincir:
Öğren → derinleştir → karar ver
mantığıyla çalışır.
6️⃣ Neden ReLU → ReLU → Softmax?
ReLU:
Hızlı öğrenme
Vanishing gradient yok
Ara katmanlar için ideal
Softmax:
Olasılık üretir
Sınıflar arasında seçim yapar
Sadece çıkışta kullanılır
Tek cümlelik net özet
Bu üç katman, bir MNIST görüntüsünü önce basit özelliklere, sonra daha karmaşık temsillere dönüştürür ve en sonunda hangi rakam olduğuna dair olasılıksal bir karar üretir.
9
TERM
bu satır, eğitim başlamadan önce yapılan son ve en kritik ayardır.

DEFINITION
Bu satırın anlamı şudur:
“Modeli nasıl öğreneceğim,
neyi yanlış sayacağım,
ve başarıyı nasıl ölçeceğim?”
1️⃣ compile ne demek? (büyük resim)
compile, modelin artık eğitime hazır hale getirilmesi demektir.
Bundan önce:
Katmanları tanımladık (beynin yapısı)
Burada:
Nasıl öğreneceğini söylüyoruz
2️⃣ optimizer='adam' → model nasıl öğrenecek?
Sezgisel anlatım
Optimizer şunu yapar:
“Hata büyükse ağırlıkları hangi yönde, ne kadar değiştireyim?”
Adam, bu işi:
Akıllı
Otomatik
Hızlı
şekilde yapan bir yöntemdir.
Neden Adam?
Öğrenme hızını kendisi ayarlar
Gürültülü gradyanlarla iyi çalışır
Yeni başlayanlar için çok güvenlidir
Kısaca:
“Ağırlıkları güncellerken akıllı davran.”
3️⃣ loss='sparse_categorical_crossentropy'
→ model neyi yanlış sayacak?
Loss neydi?
Loss:
“Tahminim ne kadar yanlış?”
Bunu sayısal bir değer olarak ölçer.
Neden categorical crossentropy?
Çünkü:
Bu bir çok sınıflı problem
10 rakam var (0–9)
Çıkışta softmax var
Yani:
“Bir sınıf doğru, diğerleri yanlış.”
Neden sparse?
Çünkü etiketlerimiz şöyle:
y_train = [5, 0, 4, 1, 9, ...]
Yani:
Tek bir sayı
One-hot değil
Eğer etiketler şöyle olsaydı:
[0,0,0,0,0,1,0,0,0,0]
o zaman categorical_crossentropy kullanırdık.
4️⃣ metrics=['accuracy']
→ biz sonucu nasıl yorumlayacağız?
Accuracy neyi ölçer?
“Model doğru mu bildi, yanlış mı?”
En yüksek olasılığı verdiği sınıf doğruysa → 1
Yanlışsa → 0
Epoch sonunda:
Doğru tahminlerin oranını gösterir
⚠️ Önemli:
Accuracy öğrenmeyi sağlamaz
Sadece raporlama içindir
5️⃣ Hepsini tek cümlede toparlayalım
Bu satır şunu söylüyor:
“Model, hatasını cross-entropy ile ölçecek,
ağırlıklarını Adam optimizer ile güncelleyecek,
ve bize başarısını accuracy olarak raporlayacak.”
6️⃣ Bu ayarlar neden birbirine uyumlu?
Parça Neden doğru?
Softmax Çok sınıflı çıktı
Cross-Entropy Olasılık tabanlı hata
Adam Hızlı ve stabil öğrenme
Accuracy İnsan için anlaşılır ölçüm
7️⃣ Küçük ama kritik not
Softmax + Cross-Entropy birlikte kullanılır çünkü:
Gradient daha stabil olur
Öğrenme hızlanır
Sayısal problemler azalır
10
TERM
Modeli eğitme

DEFINITION
Ne anlama geliyor?
Epoch = tüm veri setini 10 kez gör
Batch size = 128
Mini-batch gradient descent
📌 128:
GPU dostu
Dengeli gürültü
Hızlı eğitim
11
TERM
Test setinde değerlendirme

DEFINITION
Çok önemli:
Test verisi eğitimde görülmedi
Gerçek performans burada ölçülür
12
TERM
Tahmin ve Confusion Matrix

DEFINITION
Ne yapıyor?
Softmax çıktılarından
En yüksek olasılığı seçiyor
13
TERM
Confusion Matrix

DEFINITION
Ne gösterir?
Hangi rakamlar birbiriyle karışıyor
Modelin zayıf noktaları
📌 Örn:
4 → 9
5 → 3
14
TERM
Sınıf bazlı doğruluklar

DEFINITION
Anlamı:
“Model 7’leri ne kadar iyi biliyor?”
“Hangi sınıfta zorlanıyor?”
Bu çok profesyonel bir analiz adımıdır.
15
TERM
Genel akış (bunu kafana yaz)
Veri yükle
Görselleştir
Normalize + reshape
Model kur
Compile
Train
Test
Analiz
14️⃣ Özet (tek cümle)
Bu kod, MNIST rakamlarını sınıflandırmak için veriyi hazırlayan, çok katmanlı bir sinir ağı eğiten ve sonuçları hem genel hem sınıf bazlı olarak analiz eden tam bir eğitim hattıdır.
DEFINITION
✅️
Others Also Like
Discover similar quizzes that might interest you



Sign in to join the discussion
No comments yet. Be the first to share your thoughts!